Research + Deployment Project
3D Scene Flow: Auto-Labeling & Production Deployment
An unsupervised point- and occupancy-level 3D scene-flow auto-labeling system, two deployable flow networks, an ultra-light production head, and full ONNX → TensorRT / Horizon J6E deployment.
Overview
What is this project about?
A 3D motion-estimation stack for autonomous driving: an unsupervised auto-labeling system that assigns a 3D scene-flow vector to every LiDAR point and every occupancy cell, validated by lifting the accuracy of existing flow estimators, distilled into an ultra-light production head, and deployed end-to-end through ONNX, TensorRT (Orin) and the Horizon J6E toolchain.
Overview
Give every point — and every occupancy cell — a motion vector, with no human labels
3D scene flow is the dense per-point 3D motion field between two LiDAR sweeps — the geometric backbone for dynamic-object reasoning, velocity estimation and occupancy-flow prediction. Hand-labeling it is effectively impossible. This project built an unsupervised auto-labeling system that assigns a motion vector to every point and every occupancy (occ) cell, used those labels to sharpen existing flow estimators, distilled the result into an ultra-light production head, and shipped the whole stack through ONNX → TensorRT (NVIDIA Orin) and the Horizon J6E toolchain.
An unsupervised 3D scene-flow & occ-flow auto-labeler
The heart of the project: a self-supervised system that takes raw LiDAR sweeps and produces a dense 3D motion label for every point and every occupancy cell — no manual annotation in the loop. These auto-labels become the training signal for every downstream flow model.
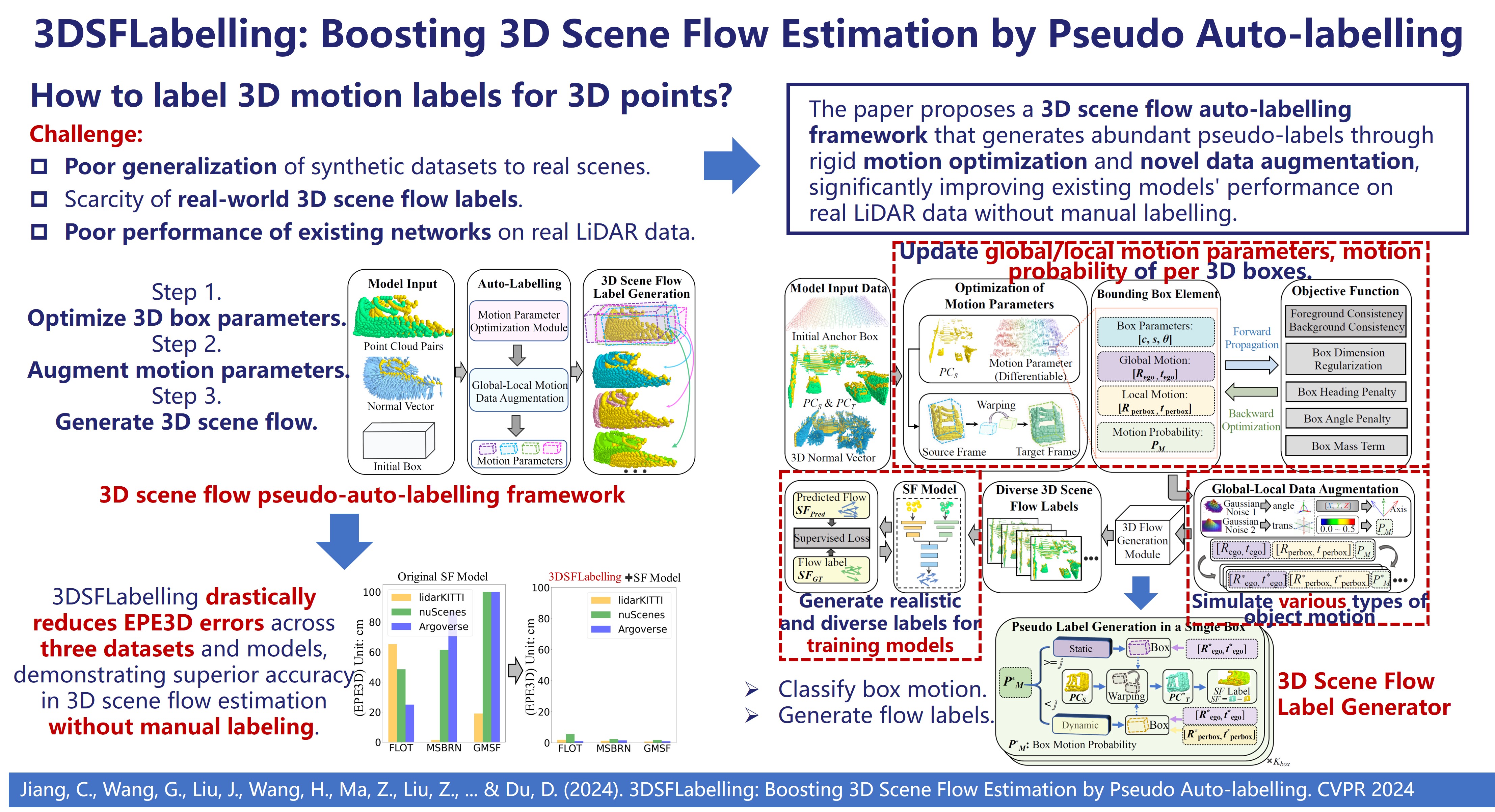
Consecutive LiDAR sweeps
- Paired point clouds Pt, Pt+1 + ego-pose; no flow ground truth required
Dense motion field
- Predict a 3D vector per point and per occ cell; ego-motion compensated so only true object motion remains
Consistency objectives
- Nearest-neighbour / cycle / smoothness constraints replace human labels with geometry
Point- & occ-flow labels
- A reusable label bank that trains and stress-tests every downstream estimator
Auto-labels lift existing flow estimators
The acid test for a labeling system is whether its labels make other models better. Feeding our auto-labels into established 3D scene-flow estimators improved their prediction accuracy substantially — direct evidence that the generated supervision is both correct and useful.
Baseline estimators
Original supervision
Trained on their native, limited flow signals
Weaker on fast, distant and sparse objects
+ our auto-labels
Substantially sharper
Same architectures, richer dense supervision
Consistent accuracy gains across methods

An ultra-light 3D scene-flow head — two design routes
For mass production the flow predictor must be tiny and embedded-friendly. We explored two routes for the production head and compared them head-to-head: a graph-convolution + mathematical-constraint design, and a pure point-cloud deep-learning design fit directly to supervision.
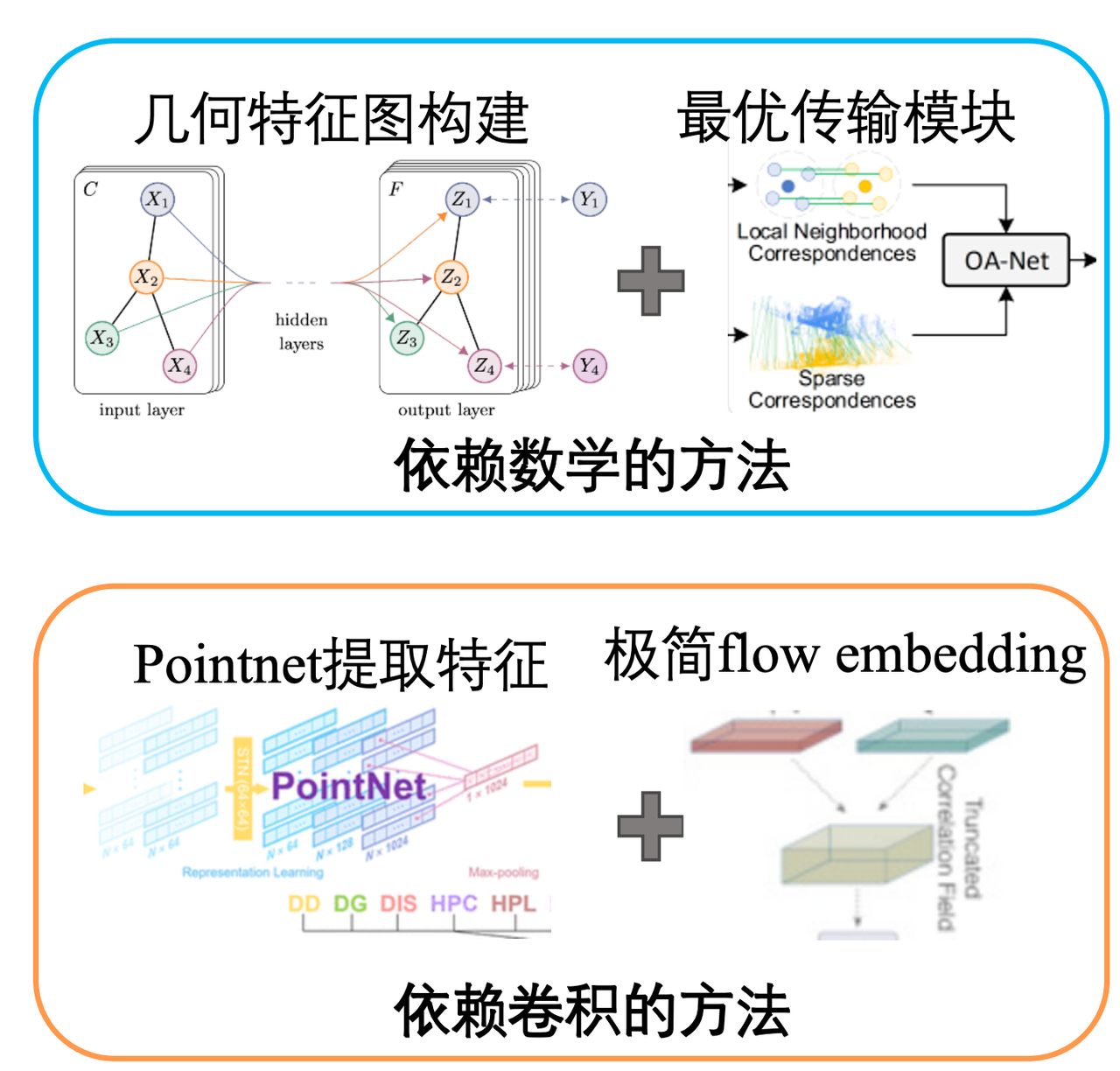
Route A · Graph-conv + math
Geometry-guided
Graph convolution over local neighbourhoods
Explicit rigidity / smoothness constraints
Robust & interpretable on structured motion
Route B · Pure deep-learning
Data-driven
Point-cloud network regresses flow end-to-end
Fit directly to the auto-generated labels
Simplest graph to export and quantize
ONNX → TensorRT / Horizon J6E, with occ-flow inference
The trained head was exported to ONNX, optimized with TensorRT for NVIDIA Orin, and converted with the Horizon SDK toolchain for J6E. Against existing production options our solution held up well, and the same export produces the live occupancy-flow inference below.
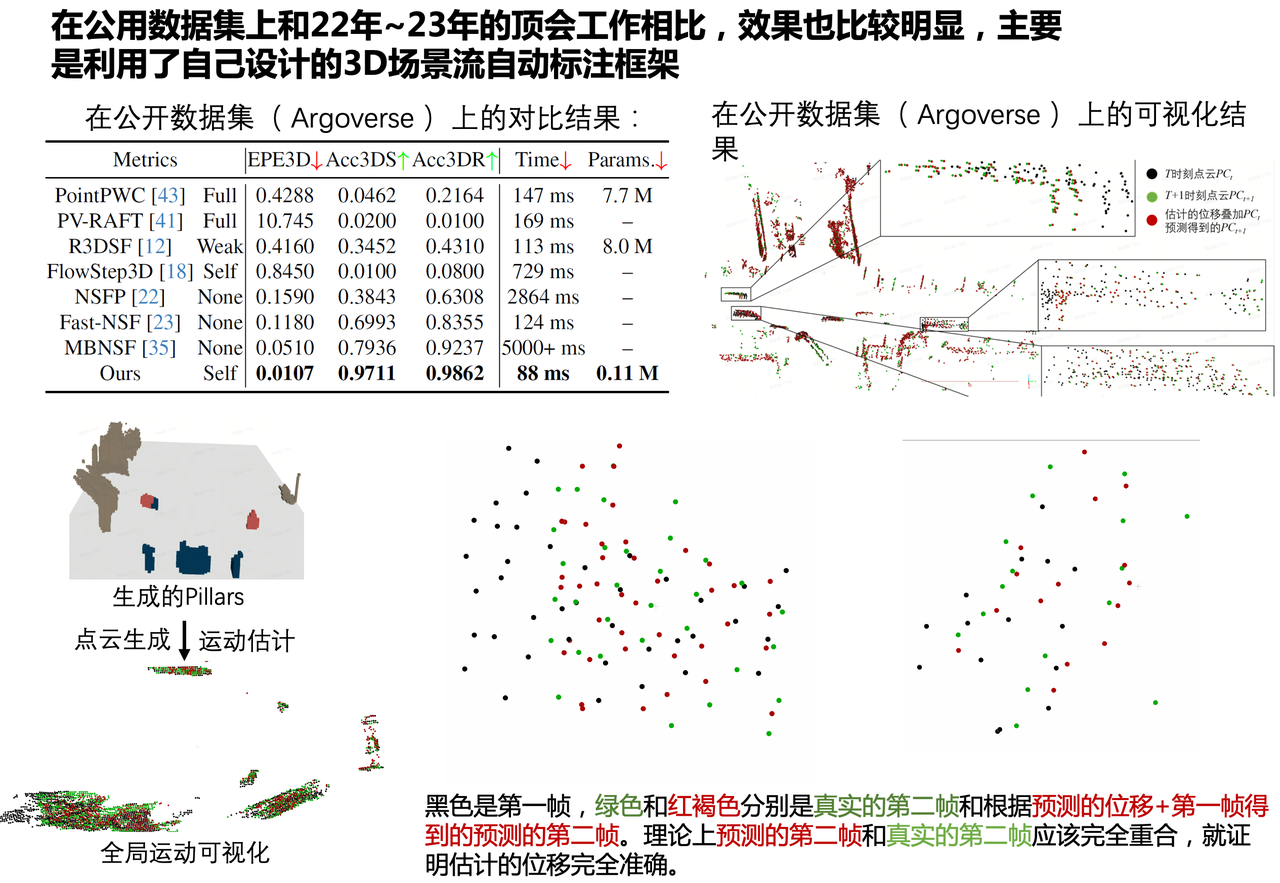
Trained model → ONNX
- Floating-point or quantized graph exported to a portable .onnx
TensorRT on Orin
- Graph & precision optimization for the Orin runtime
SDK on J6E
- Convert & quantize through the Horizon J6E toolchain
On-vehicle inference loop
- Point-cloud preprocess → cache init → normalize → inference → output parsing → perf stats
Visualization
Auto-Flow, running
The end-to-end result — dense 3D scene flow auto-labeled and predicted on real driving sequences. Plays automatically and loops.