Production Project
Road Preview: Surface-Element Segmentation
Robust segmentation of small road elements — manhole covers and speed bumps — for the road-preview / 'magic-carpet' suspension feature, hardened against hard cases and quantized for TDA4 edge deployment.
Overview
What is this project about?
A road-surface perception project for the road-preview ('magic-carpet') suspension feature: segment safety-critical small road elements — manhole covers and speed bumps — reliably under hard real-world conditions (tiny targets, water and oil stains, textureless surfaces), then compress and quantize the model to INT8 for efficient TDA4 edge inference, reaching an initial mass-production quality bar.
The Challenge
Why small road-element segmentation is hard
The road-preview feature looks ahead and segments small surface elements so the suspension can pre-adjust. The targets are tiny and the visual conditions are adversarial — three failure modes dominate.



| # | Challenge | Why it breaks naive models |
|---|---|---|
| 01 | Extremely small targets | Manhole covers and speed bumps can occupy less than 1% of the image pixels, so the signal is easily lost to pooling and down-sampling. |
| 02 | Stain / texture confusion | Water and oil stains on the road produce textures highly similar to a real manhole cover, driving false positives. |
| 03 | Textureless / color-matched | Many covers are textureless or nearly the same color as the asphalt, driving missed detections. |
Stage 1 · Train (FP32)
Segmentation training pipeline
A classic Encoder–Decoder design, tuned end-to-end for TDA4 edge deployment. The flow runs data → features → decoding → loss → optimization → evaluation, looped each epoch.
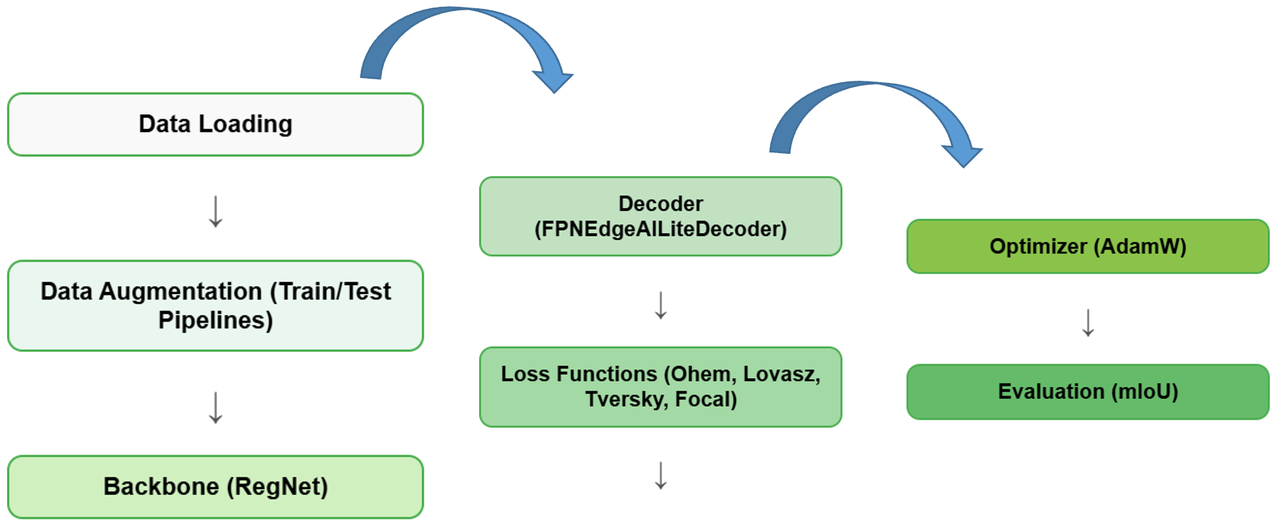
Data → feature extraction
| Module | Role |
|---|---|
| Data Loading | Reads images and their pixel-level annotation masks; supports multiple segmentation dataset formats. |
| Data Augmentation | The train pipeline applies strong augmentation (random crop / flip / color jitter); the test pipeline only normalizes. The two are strictly separated to avoid data leakage. |
| Backbone · RegNet | A regularized network found by design-space search — high compute efficiency and accuracy, ideal for edge deployment (low MAC, low memory). Emits multi-scale feature maps (C2–C5, ResNet-style). |
Decoding → losses
| Module | Role |
|---|---|
| Decoder · FPNEdgeAILiteDecoder | A lightweight FPN-based decoder built for EdgeAI (TI EdgeAI Toolbox): fuses multi-scale features, upsamples back to full resolution, and outputs a per-pixel class-probability map. |
| Loss · OHEM | Online Hard Example Mining — dynamically selects high-loss hard samples for back-propagation to mitigate class imbalance. |
| Loss · Lovász | A differentiable surrogate that directly optimizes IoU, aligned with the mIoU metric; outperforms pure cross-entropy on segmentation. |
| Loss · Tversky | A generalization of Dice loss; α/β control the false-positive / false-negative trade-off — well suited to small and rare targets. |
| Loss · Focal | Down-weights easy samples and focuses on hard pixels; effective under extreme class imbalance. |
The four losses are combined with weights so they complementarily cover the different failure modes above.
Optimization → evaluation
| Module | Role |
|---|---|
| Optimizer · AdamW | Adam with decoupled weight decay — fast convergence and good generalization, robust for CNN/Transformer-style architectures. |
| Evaluation · mIoU | Mean Intersection-over-Union — the standard segmentation metric, averaged over all classes for a fair view of long-tail performance. |
| Training loop (blue arcs) | The left arc re-enters Data Loading each epoch to stream new batches; the right arc feeds evaluation back to drive hyper-parameter tuning (LR scheduler) and early stopping. |
Stage 2 · Quantize & Compile (INT8)
From FP32 ONNX to a TDA4 TIDL binary
The trained floating-point model is compiled and quantized into a TDA4-runnable TIDL binary using TI's TIDL Model Import toolchain — three inputs feed a containerized import step.
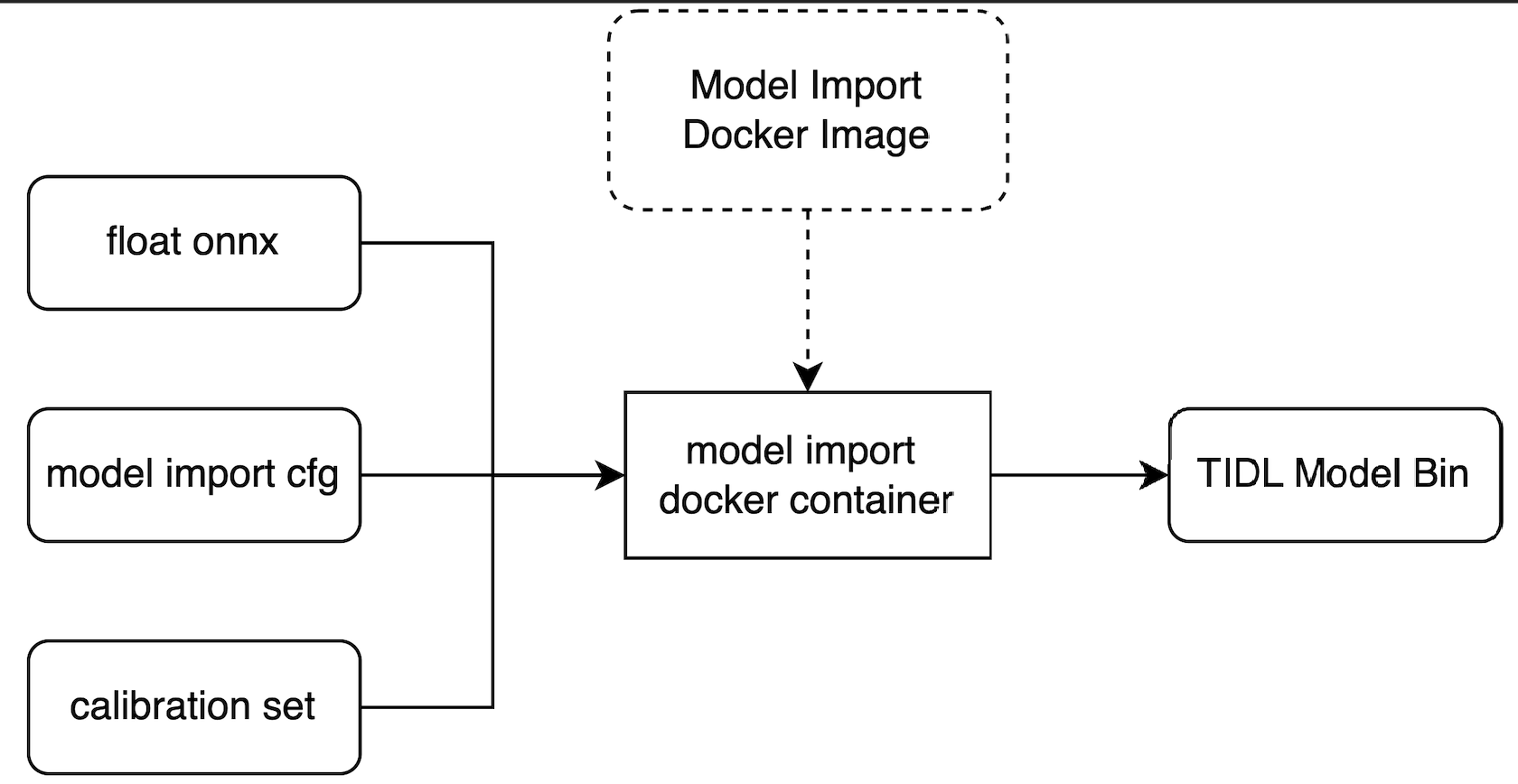
Three inputs to the import step
| Input | Role |
|---|---|
| float onnx | The exported FP32 ONNX model — full network structure and FP32 weights. |
| model import cfg | TIDL compile config: quantization bit-width (INT8/INT16), input size, target core (MMA / C7x DSP), and operator-mapping strategy. |
| calibration set | A small set of real images (~100–500) for Post-Training Quantization (PTQ) calibration — collects each layer's activation range (min/max or histogram) to set the quantization scale / zero-point. |
Inside the model-import Docker container
Why Docker? The TIDL toolchain depends on a specific TI SDK environment; the container guarantees consistency and avoids dependency conflicts. The dashed arrow means the Docker image is the container's source — provided by TI and pulled on demand.
| Step | What happens |
|---|---|
| 1 · Operator fusion | Merges Conv + BN + ReLU to cut memory traffic. |
| 2 · Quant calibration | Uses the calibration set to estimate activation distributions and derive INT8 quantization parameters. |
| 3 · Hardware-aware compile | Maps operators onto the TDA4 MMA (matrix accelerator) or C7x DSP; unsupported ops fall back to ARM. |
TIDL Model Bin
| Property | Detail |
|---|---|
| Contents | INT8 quantized weights, network topology, and hardware scheduling info. |
| Runtime | Loaded and executed directly by the TDA4 TIDL Runtime. |
| Efficiency | About 4× smaller than the FP32 ONNX, with much faster inference and significantly lower power. |
The full loop
Train → Quantize → Deploy
Stage 1 produces a high-accuracy FP32 model; Stage 2 compresses it into an edge-efficient quantized binary. Together they form a complete closed loop from training to on-vehicle inference.
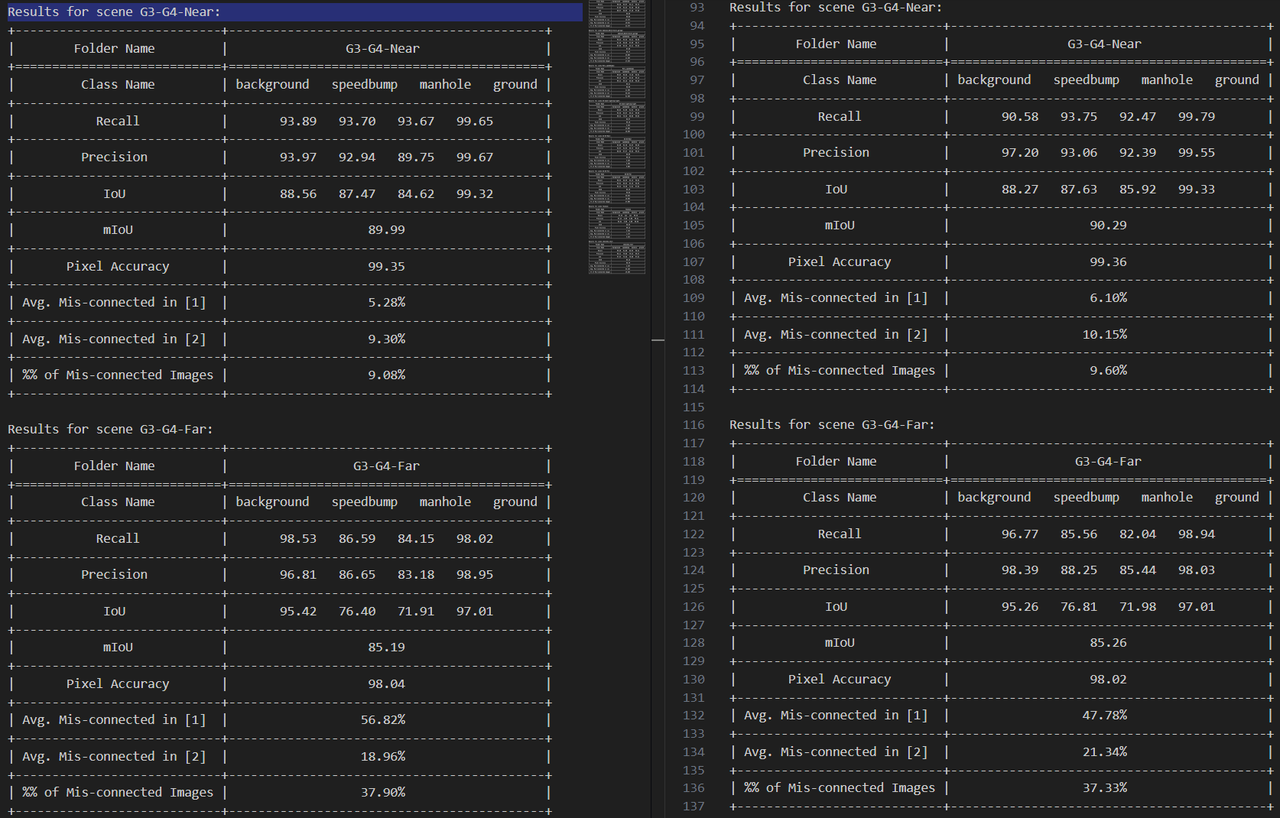
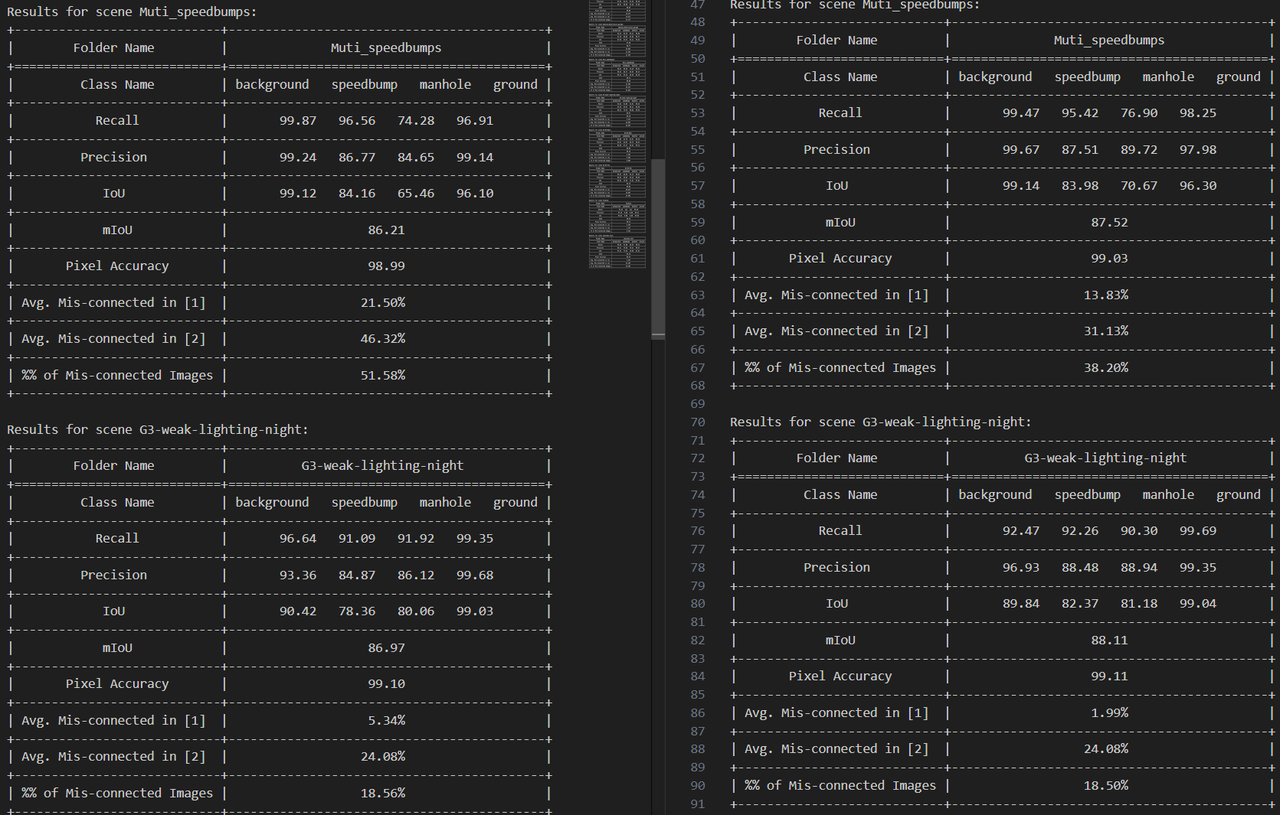
Evaluation
Quantized model on bad cases
Per-scene evaluation of the quantized model on representative hard cases — water stains, far-range targets, and complex multi-bump / night scenes.
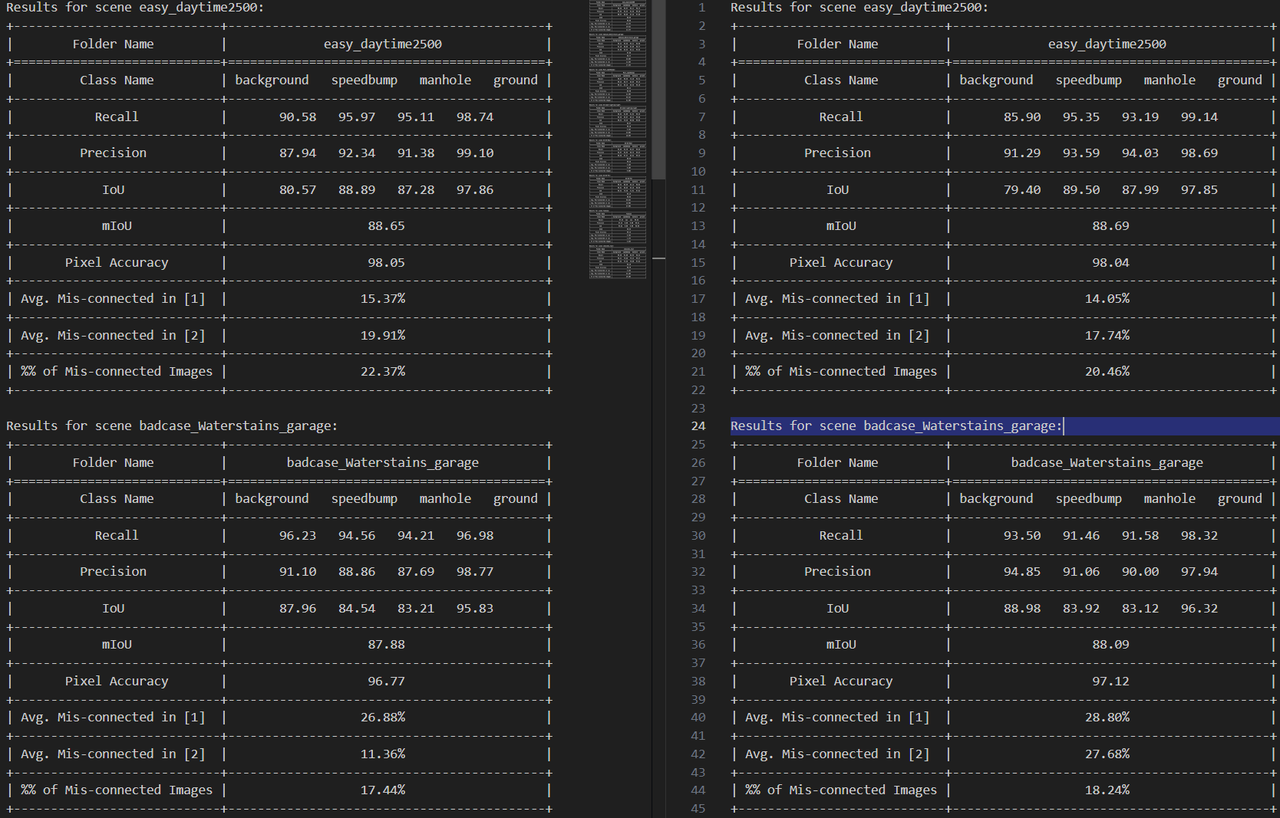
Visualizations
On-road inference replays
Selected replay clips — all play automatically and loop.