Research Project
Controllable Surround-View Driving Generation
A controllable multi-view world model for driving: 3D layout + map + multi-granularity control signals injected into a diffusion process to generate geometrically-consistent 4V / 7V / 11V images and video — for data augmentation and open-loop simulation.
Overview
What is this project about?
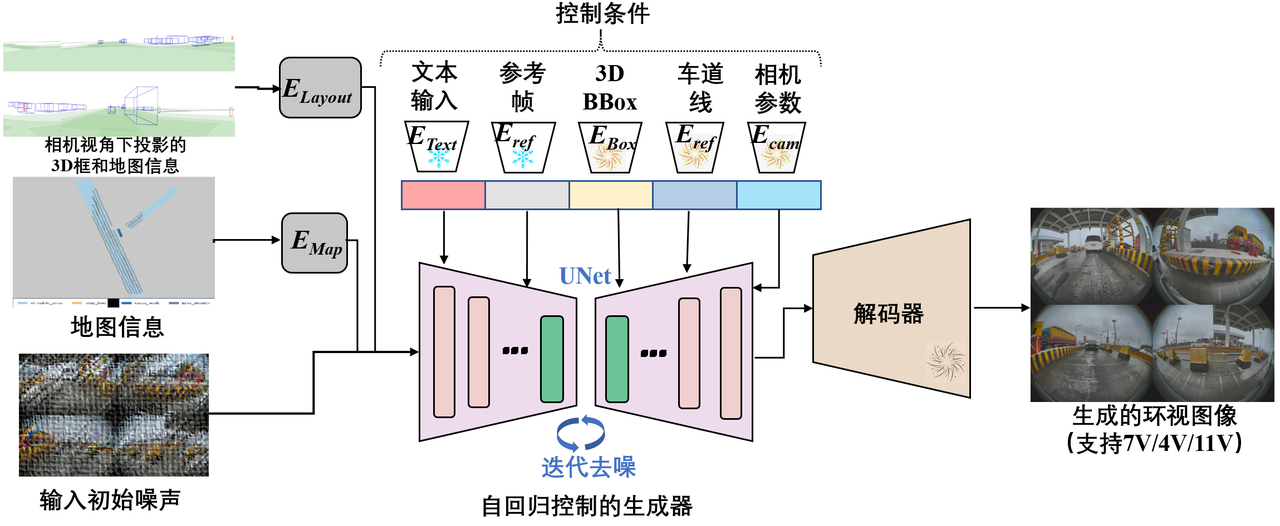
Built a controllable surround-view driving generator that compresses 3D boxes and maps into spatial conditions, encodes text / reference frames / lanes / camera calibration into condition tokens, and injects them into a UNet diffusion backbone — producing cross-camera-consistent 4V / 7V / 11V images and video for data augmentation and open-loop simulation, evolving from OpenSora 1.0 + SD 3.5 to a MagicDrive-fused in-house model.
4V / 7V / 11V surround
3D layout + HD map
Text · refs · lanes · rig tokens
UNet diffusion backbone
OpenSora → MagicDrive fusion
4V·7V·11VCamera configurations supported
6+Control signals per generation
2 usesAugmentation · open-loop simulation
V2RGB, depth, ego-pose control
Conditioned diffusion pipeline
Scene replacement for augmentation




Surround video generation
V2: depth and ego control
Unbalanced real dataGenerate rare scenes on demand
Cross-camera driftProject boxes and maps per view
Style-only controlFuse layout, map, text, rig tokens
RGB-only worldsExtend to depth and ego-pose control
OmniNWM.
After my departure, former colleagues led the follow-up OmniNWM direction: github.com/Ma-Zhuang/OmniNWM.
My role.
Built the controllable driving generation pipeline at a high level: structured conditions, diffusion integration, and sanitized visualization for augmentation and open-loop simulation.
Confidentiality note.
PhiGent Robotics research. Only sanitized generation results and high-level pipeline descriptions are shown; dataset details and internal evaluation metrics are omitted. The OmniNWM follow-up was led by former colleagues after my departure and is credited below.