Production + Research Project
Autonomous Lawn-Mower Robot Perception
A safety-critical LiDAR and multimodal perception stack for autonomous loading/unloading, slope traversal, grass-obstacle detection, and embedded deployment.

Overview
What is this project about?
The robot has to drive itself off a transport vehicle, reach the lawn, mow, and return — so I built its safety-critical perception stack across four modules: ramp detection for self loading/unloading, 3D grass-obstacle detection (geometry first, then camera–LiDAR fusion), an MCU-deployed 2D BEV safety detector, and a dual-attention LiDAR–vision fusion study.
System Architecture
Four perception modules, one safety stack
From a transport vehicle to the lawn and back, the robot leans on a layered perception stack. Switch between the four modules below to see what each one does, the tools behind it, the algorithm pipeline, and the on-vehicle result.
Module A · PCL + Eigen + OpenCV
Up / down ramp detection
Detect a drive-on ramp and its four boundary lines from a solid-state LiDAR point cloud, so the robot can autonomously and stably load and unload itself onto a transport vehicle.
Raw point cloud
- Solid-state LiDAR stream, vehicle-front field of view
Crop, downsample, denoise
- ROI crop: x∈[0,20] · y∈[−5,5] · z∈[−2,2] m
- VoxelGrid downsample, leaf = 0.05 m
- StatisticalOutlierRemoval denoising
Normals + candidate tilted planes
- KdTree radius search r = 0.3 m → per-point normals
- Tilt constraint: normal–Z angle θ∈[5°,35°]
- RegionGrowing (normal diff <5°, point–plane <0.05 m) → N candidate clusters
RANSAC-like plane refinement
- ×100 iters: weighted 3-point sampling → plane; validity θ∈[5°,20°]; count inliers (<0.05 m); keep max set
- SVD least-squares on inliers → precise plane {n, d}
Multi-rule scoring → best ramp
- Weighted score Score = Σ wᵢ·sᵢ → highest candidate is the target ramp (Score < 0.4 → “not detected”)
| Criterion | Weight | Rule |
|---|---|---|
| Slope plausibility | 0.30 | θ∈[5°,20°] scores full |
| Projected area | 0.20 | larger is better (cap 15 ㎡) |
| Position / heading | 0.20 | front, 2–15 m |
| Planarity (RMSE) | 0.15 | smaller residual is better |
| Shape compactness | 0.10 | reasonable aspect ratio |
| Ground connection | 0.05 | low end joins the ground |
Local frame + boundary points
- Frame: n = Z-axis, downhill = X-axis; project inliers → 2D (u, v)
- Longitudinal 20 strips → 2 long edges; lateral 10 strips → 2 short edges → 4 boundary sets
Outlier removal
- 1D spacing-jump: gap > 3× mean → drop isolated points
- Sliding-window median (win = 5): deviation > 0.1 m → drop → 4 clean edge sets
Four boundary-line fitting
- RANSAC (30 iters) 2-point line + inliers
- TLS total least squares via SVD → precise line; endpoints by projection → 4 directed segments
Post-processing + RampInfo
- Pairwise intersection → 4 corners; validate (opposite edges ∥ <5°, width [1.5,5] m, length [2,20] m); EMA smoothing α = 0.3
- Output RampInfo { slope_angle, width, length, corners[4], boundary_lines[4], plane, confidence }
Module B · two versions
Grass obstacle detection
Detect 3D obstacles on grass — first with a pure point-cloud geometric pipeline (V1), then upgraded with camera–LiDAR semantic fusion for class-aware, more robust detection (V2).
Geometry-only pipeline — PCL
Raw point cloud
- Solid-state LiDAR
Filter chain
- PassThrough crop → VoxelGrid downsample → StatisticalOutlierRemoval
Ground segmentation
- PMF morphological filter → RANSAC plane (normal∠Z < 15°); ground points discarded
Euclidean clustering
- KD-Tree neighbor search r = 0.4 m · min 20 · max 5000 pts
PCA bounding box + rules
- PCA → OBB; constraints h∈[0.1,2] · w∈[0.1,3] · l∈[0.1,5] m · h/w < 5
3D obstacles
- Position / size / distance = √(cx² + cy²)

Camera–LiDAR semantic fusion — TensorRT
Point cloud
- Solid-state LiDAR
Image
- RGB camera
2D bounding boxes
- Per-frame 2D BBox list
Semantic mask
- Ground / obstacle pixel mask
Extrinsic point ↔ pixel
- Camera–LiDAR extrinsics inject semantics into each 3D point
Mask-based segmentation
- mask = ground → discard; obstacle → keep (replaces RANSAC)
2D-guided clustering
- Cluster points inside each BBox; associate 2D detection ↔ 3D cluster
Geometric filter
- PCA → OBB with the same V1 rule constraints
Triple-score fusion
- 0.4 × geometry + 0.4 × 2D IoU + 0.2 × semantic consistency
Class-aware 3D obstacles
- 3D obstacles with category label and confidence

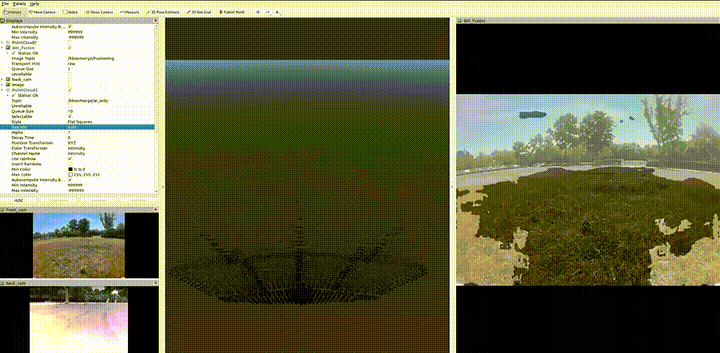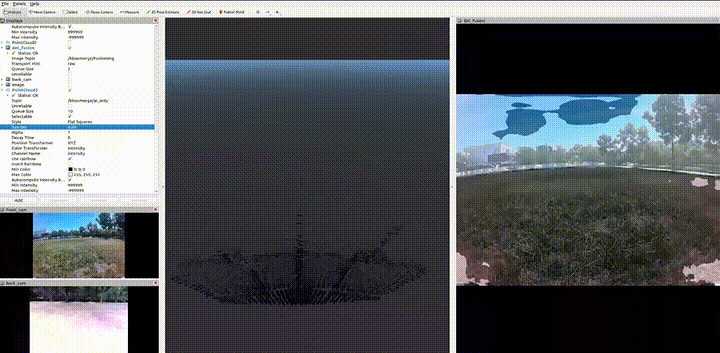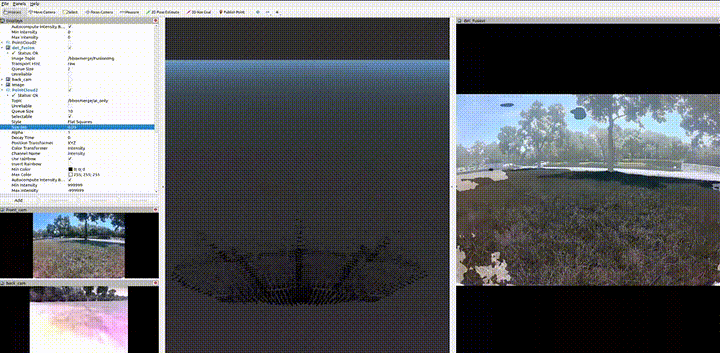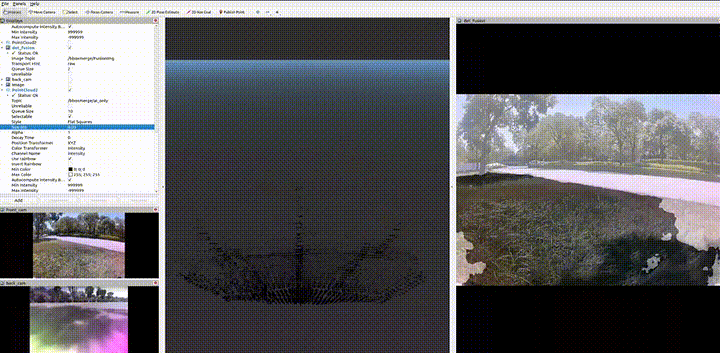
Module C · STM32H7 MCU
Embedded 2D BEV safety detection
A lightweight 2D BEV obstacle detector deployed on an STM32H7 microcontroller — static memory plus integer optimization deliver 110 fps real-time detection that passes functional-safety testing.
Raw point cloud
- Solid-state LiDAR stream
Point-cloud preprocessing
- ROI crop (5 m × 5 m); ground removal z < −0.1 m
- Invalid filter (range = 0 / NaN); height clamp 0.05–2.5 m
BEV projection
- Cell index idx = (x − origin) / reso
- Per-cell point count; height diff max_z − min_z
Obstacle decision
- Density threshold count > 3; height diff > 0.1 m
- Connected components (8-neighbor merge)
BEV obstacle list
- Danger level + nearest-obstacle BEV coordinate

Module D · pre-research
Dual-attention LiDAR–vision fusion
A pre-research study (toward a company paper KPI) on dual-attention fusion that correlates scene geometry and texture features for stronger LiDAR–vision 3D detection.
LiDAR features
- 3D scene-geometry encoding
Image features
- 2D appearance / texture encoding
Fast correspondence
- Pre-compute point ↔ pixel index so fusion stays cheap at runtime
Explicit correspondence
- Geometric point ↔ pixel matching
Query-style attention
- Learned cross-modal attention weights
Geometry × texture interaction
- Two attention streams couple structure and appearance into a shared representation
Robust 3D detection
- Stronger on small objects, sparse LiDAR, and degraded images