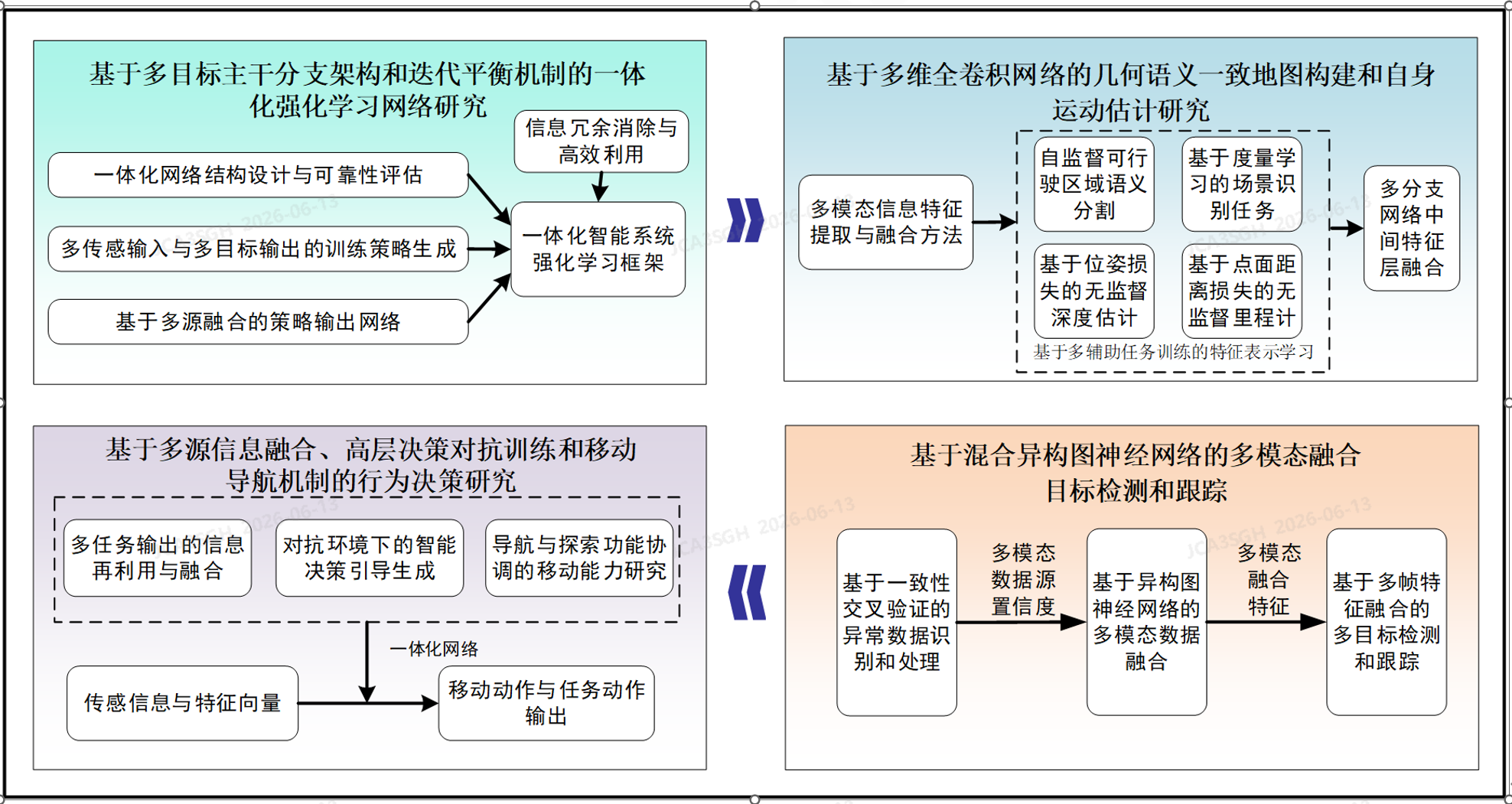
Research Project
Integrated Perception, Planning, and Decision-Making Network
A unified multi-task network that fuses RGB, LiDAR, and infrared for closed-loop perception, planning, and decision-making in simulation.
Overview
What is this project about?
A unified multi-task framework that fuses multi-modal sensors (RGB, LiDAR, infrared) through attention-based feature fusion — jointly solving geometric–semantic mapping, unsupervised depth and odometry, multi-object detection and tracking, and closed-loop behavior decisions inside one end-to-end trainable network.
System Architecture
One model, four interdependent abilities
Heterogeneous sensor streams are encoded by modality-specific extractors, then fused by interactive cross- and self-attention into a single representation that drives perception, reconstruction, and decision heads — forming a closed-loop perception → planning → decision pipeline.
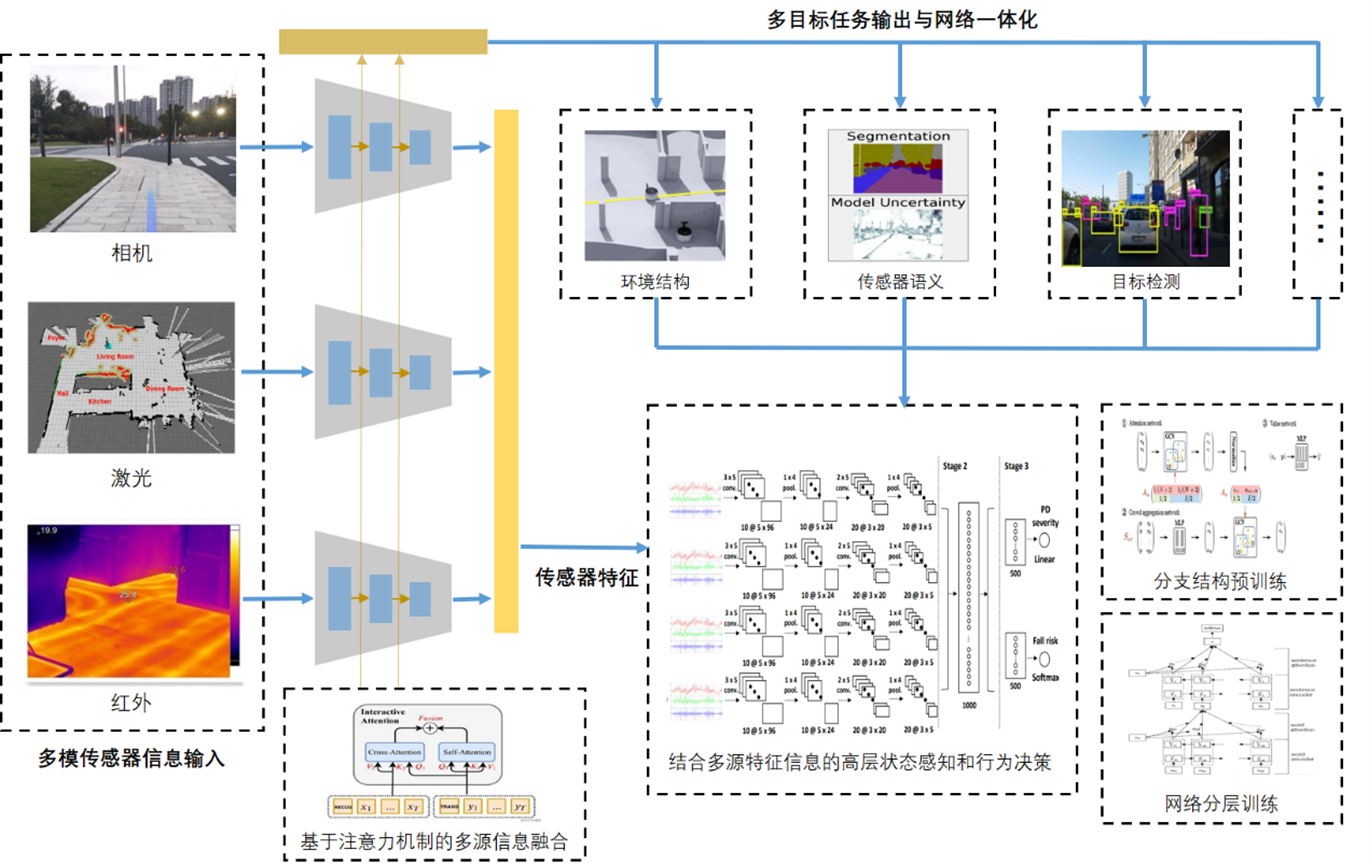
Module Breakdown
Four research modules
Switch between the four modules to see what each one does, the pipeline behind it, and the simulation result.
Module 01 · Webots + YOLOv8
2D detection and multi-object tracking
Render a virtual scene in Webots, detect objects per frame, then keep stable IDs and trajectories across time.
Webots simulation
- Virtual scene → sensor model → RGB camera → frame stream
YOLOv8 inference
- Preprocess / normalize → inference → confidence filter + NMS → boxes + class + score
Hungarian + Kalman
- IoU / feature matching → Kalman predict & update → ID assignment and track management
ID + trajectory + velocity
- ID-tagged video stream with trajectories overlaid in the simulator
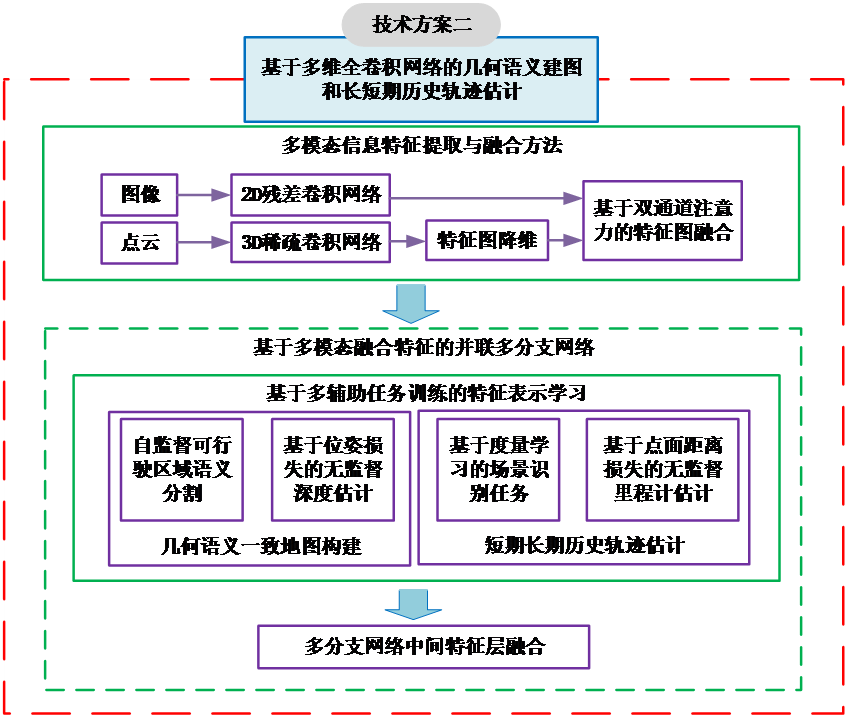
Module 02 · 2D ResNet ‖ 3D Sparse CNN
Joint geometry–semantic estimation
Encode image and point cloud separately, fuse them with dual-channel attention, and co-train four auxiliary tasks for a geometry–semantic consistent representation.
Image (2D)
- 2D residual CNN encoder
Point cloud (3D)
- 3D sparse CNN encoder
Dual-channel attention
- Align & merge features → joint geometry–semantic representation
Dense scene
- Depth-aware semantics
Ego motion
- Scaled pose → 3D map
Module 03 · ROS
Monocular visual SLAM with dense mapping
A real-time ROS pipeline: track the camera, optimize the graph, and reconstruct a dense map from a single camera.
Tracking
- ORB features → init → keyframe selection → pose optimization (+ relocalization)
Graph optimization
- Local BA ↔ loop closure (DBoW) ↔ global pose-graph
Reconstruction
- Monocular depth → reprojection → TSDF / OctoMap fusion + voxel denoising
Three map products
- /dense_pointcloud · /octomap_3d · /map_2d_grid

Module 04 · Webots closed-loop
Perception → planning → decision
Perception feeds planning, planning feeds an FSM / RL decision agent, and the action loops back to the vehicle in simulation.
Understand the scene
- Detection → obstacles · segmentation → drivable area · depth → distance · SLAM → map · odometry → ego pose
Find a path
- Global A* / Dijkstra → local DWA / MPC → collision check & avoidance
Choose an action
- FSM / RL agent with reward shaping → accelerate / brake / steer
Act & evaluate
- Vehicle executes → metrics (success / collision rate, ATE, map IoU) → iterate