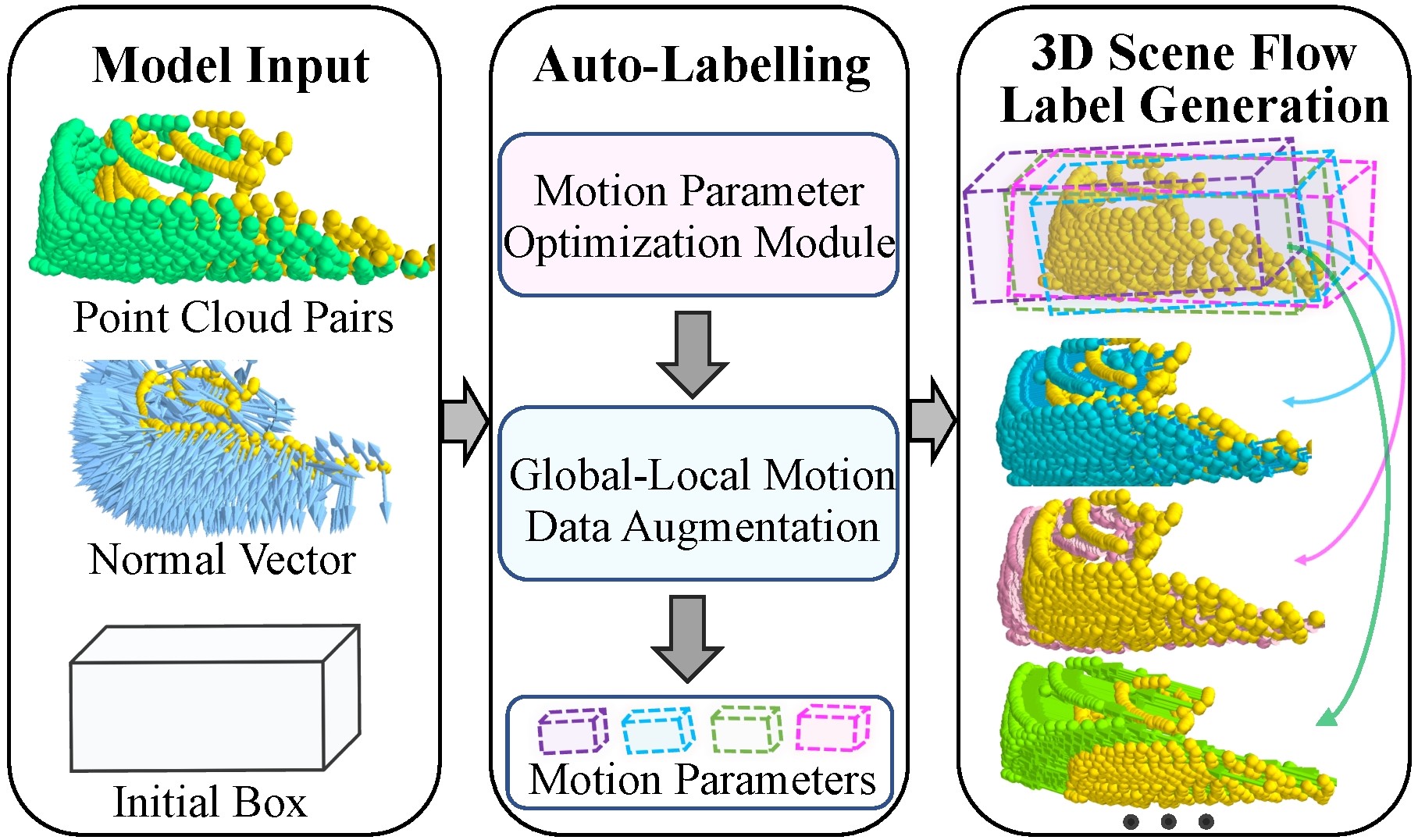
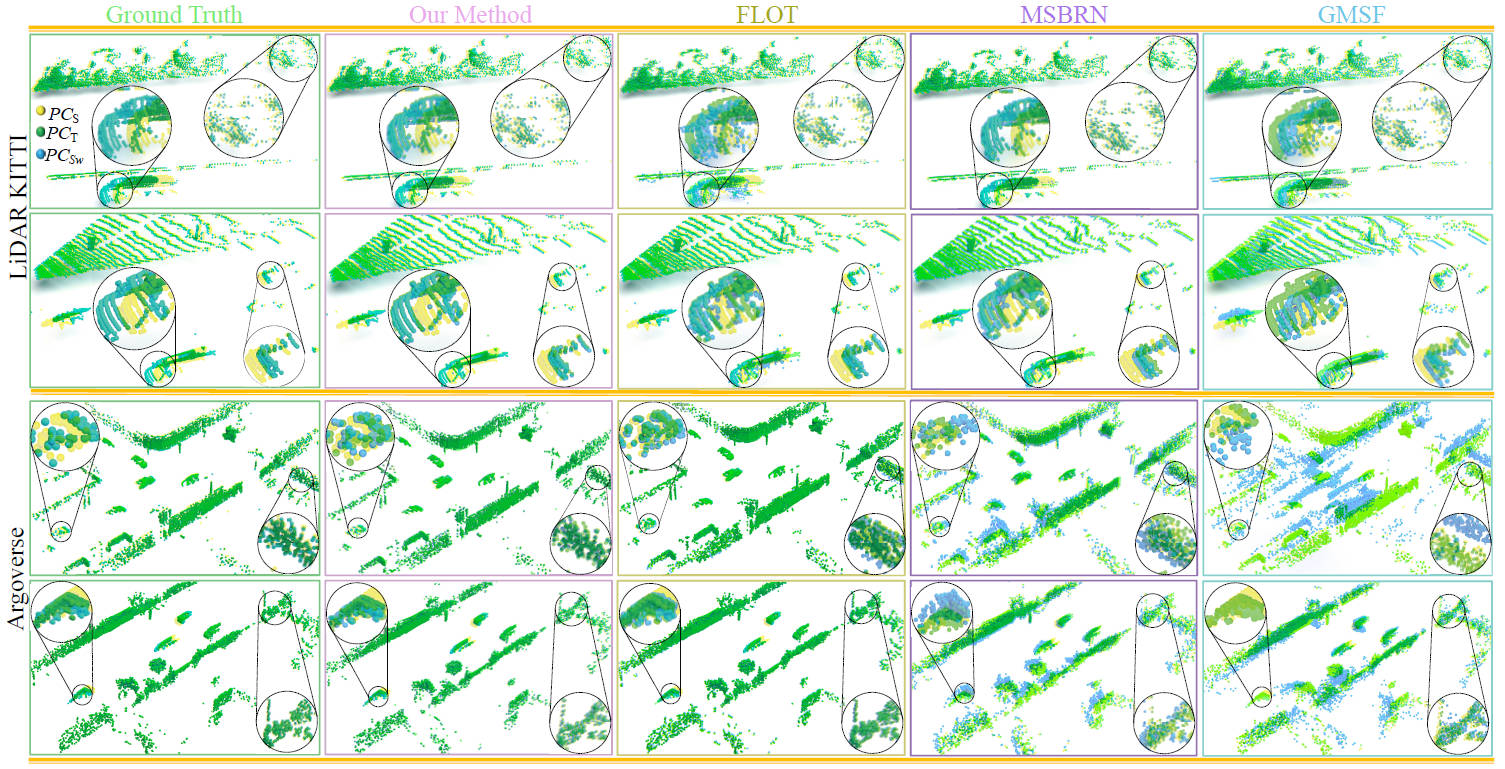
Method
From anchor boxes to millions of flow labels
Optimize per-object rigid motion, then augment it into diverse, photorealistic supervision.

01 — INPUT
Boxes & point pairs
3D anchor boxes, a source/target point-cloud pair and their coarse normal vectors enter the optimizer.
02 — OPTIMIZE
Rigid motion decomposition
Six objective functions inversely tune box, global and local motion parameters into per-object rigid movements.
03 — AUGMENT
Generate flow labels
Global-local augmentation samples K motion sets, synthesizing target clouds and abundant scene-flow labels.