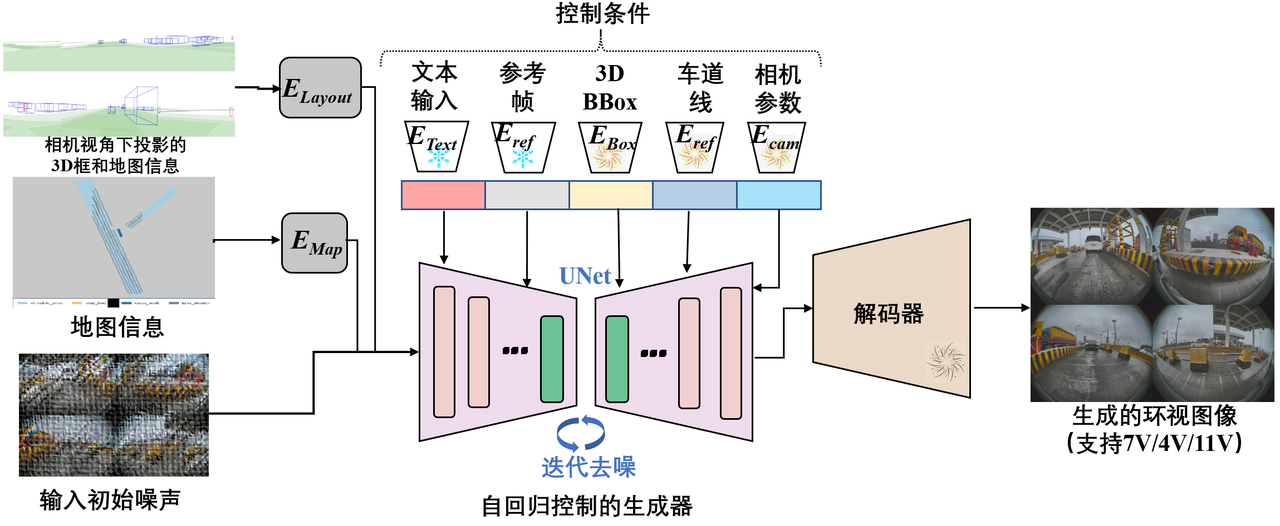
2.1 DriveDreamer-2: LLM-Enhanced World Models for Diverse Driving Video Generation
DriveDreamer-2 通过集成大型语言模型(LLM)增强的世界模型,能够生成多样化的驾驶视频。系统基于文本提示生成符合交通规则的高清地图(HDMap),并确保生成视频的时空一致性,为自动驾驶系统提供高质量的数据支持。
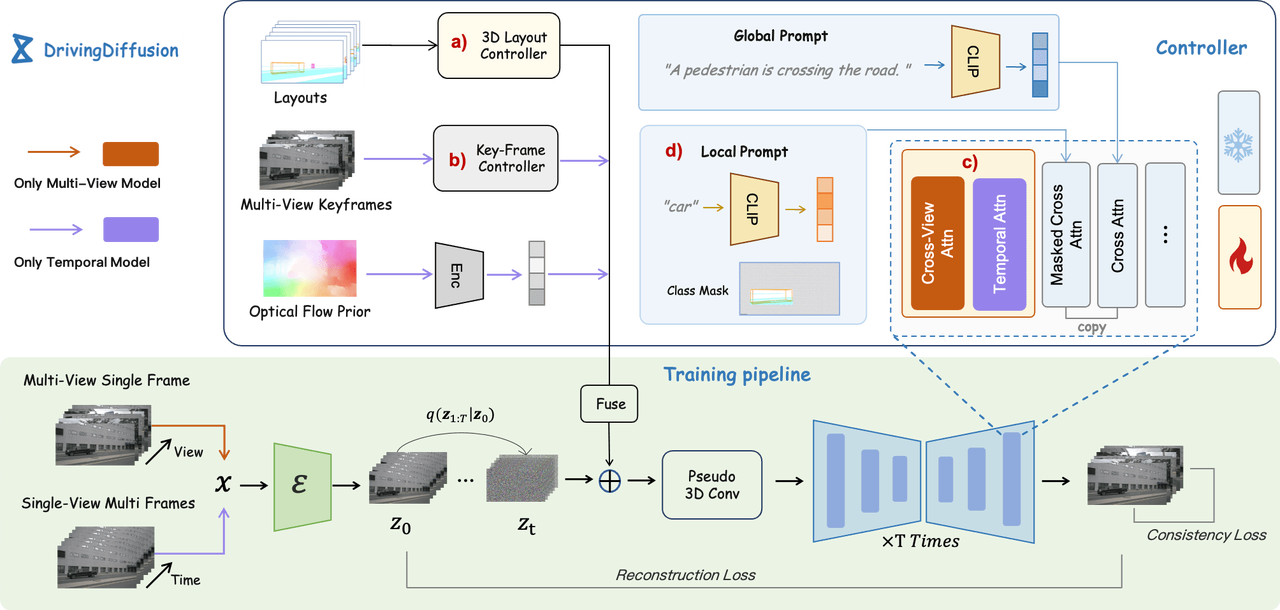
2.2 DrivingDiffusion: Layout-Guided Multi-view Driving Scene Video Generation with Latent Diffusion Model
DrivingDiffusion 是一个时空一致的多视图视频生成框架,利用潜在扩散模型(Latent Diffusion Model)指导的布局生成,确保多视角下的视频内容一致且连贯。该框架通过多视图单帧生成、单视图视频生成以及后处理优化,显著提升了生成视频的质量与一致性。