1.1 算力资源约束
- TDA4平台资源受限
- 模型复杂度与参数量需严格控制
- 浮点模型与定点模型一致性对齐
1.2 目标特征挑战
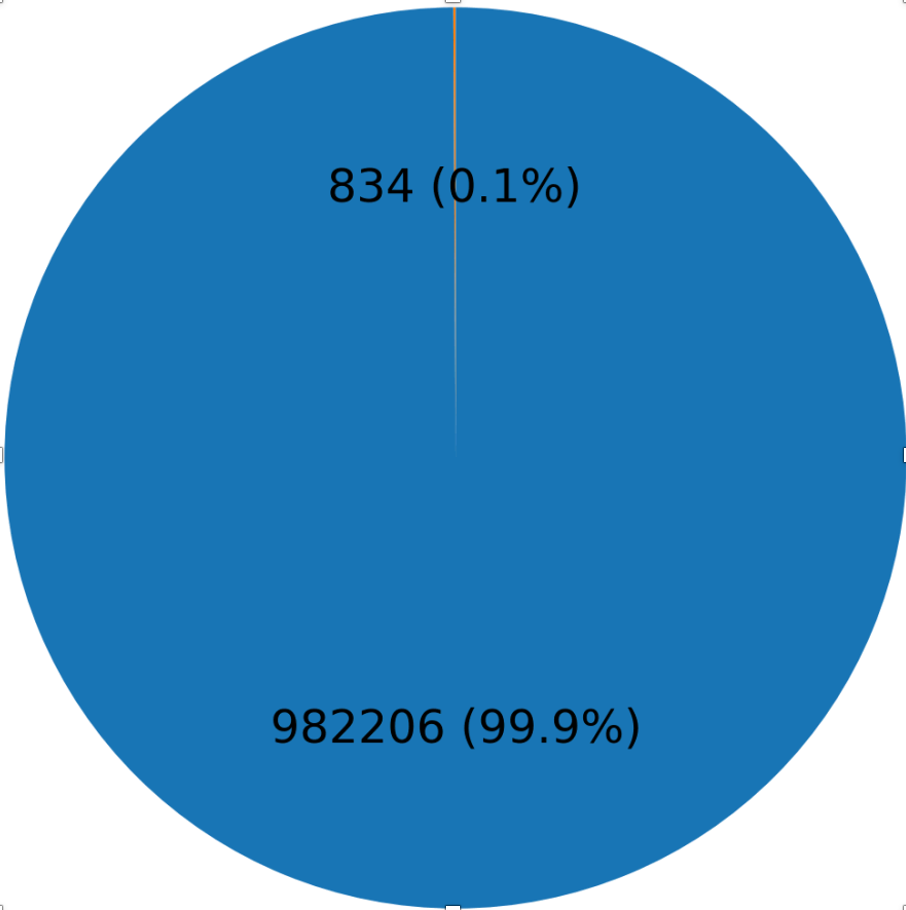
- 尺度失衡:场景尺度大而目标尺寸小(目标像素占比<1%)
- 特征模糊:目标形状复杂,目标-背景纹理相似度高
精准分割路面区域,优化深度学习模型部署




自适应选择损失值较高的困难样本进行训练,提升模型对难例的学习能力。该损失函数通过对样本进行排序,仅保留损失较大的top-k个样本参与反向传播。
class OhemCrossEntropy(nn.Module):
def __init__(self, thresh=0.7, min_kept=100000):
super(OhemCrossEntropy, self).__init__()
self.thresh = thresh
self.min_kept = min_kept
self.criterion = nn.CrossEntropyLoss(ignore_index=-1)
def forward(self, pred, target):
# 计算每个像素的损失
pixel_losses = self.criterion(pred, target).view(-1)
# 选择 top-k 损失值
sorted_losses, indices = torch.sort(pixel_losses, descending=True)
if len(sorted_losses) < self.min_kept:
kept_losses = sorted_losses
else:
kept_losses = sorted_losses[:self.min_kept]
return kept_losses.mean()
直接优化IoU评估指标的凸近似,特别适合处理语义分割任务中的边界区域。通过最小化Lovász扩展来优化Jaccard指数。
其中 l̃c 是Lovász扩展,m(c)是类别c的错误向量
class LovaszLoss(nn.Module):
def __init__(self, classes='present', per_image=False):
super(LovaszLoss, self).__init__()
self.classes = classes
self.per_image = per_image
def forward(self, logits, labels):
lovasz_loss = 0
for cls in range(logits.shape[1]):
cls_pred = logits[:,cls]
cls_target = (labels == cls).float()
errors = (cls_pred - cls_target).abs()
# 计算Lovász扩展
sorted_errors, perm = torch.sort(errors, dim=0, descending=True)
intersection = cls_target[perm].cumsum(0)
union = cls_target.sum() + (1 - cls_target)[perm].cumsum(0)
iou = intersection / union
lovasz_loss += (sorted_errors * (1 - iou)).mean()
return lovasz_loss
Dice Loss的一般化形式,通过α和β参数灵活调节假阳性和假阴性的权重,特别适合处理类别不平衡问题。
class TverskyLoss(nn.Module):
def __init__(self, alpha=0.3, beta=0.7):
super(TverskyLoss, self).__init__()
self.alpha = alpha
self.beta = beta
def forward(self, pred, target):
# 计算真阳性、假阳性和假阴性
TP = (pred * target).sum()
FP = (pred * (1-target)).sum()
FN = ((1-pred) * target).sum()
# Tversky指数
tversky = TP / (TP + self.alpha*FP + self.beta*FN)
return 1 - tversky
通过动态缩放因子降低易分类样本的权重,提升难分类样本的重要性,有效处理类别不平衡问题。
class FocalLoss(nn.Module):
def __init__(self, alpha=0.25, gamma=2):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
def forward(self, pred, target):
# 计算交叉熵
ce_loss = F.binary_cross_entropy_with_logits(pred, target, reduction='none')
# 计算pt
pt = torch.exp(-ce_loss)
# 计算focal loss
focal_loss = self.alpha * (1-pt)**self.gamma * ce_loss
return focal_loss.mean()
通过建模像素间的互信息来捕获空间依赖关系,提升分割结果的区域一致性和语义连贯性。
其中Σ为联合协方差矩阵,Σg和Σp为边缘协方差矩阵
class RMILoss(nn.Module):
def __init__(self, radius=3):
super(RMILoss, self).__init__()
self.radius = radius
def forward(self, pred, target):
# 提取局部区域
n = (2*self.radius + 1)**2
local_pred = F.unfold(pred, 2*self.radius+1)
local_target = F.unfold(target, 2*self.radius+1)
# 计算协方差矩阵
joint_cov = torch.matmul(local_pred, local_target.transpose(-1,-2)) / n
pred_cov = torch.matmul(local_pred, local_pred.transpose(-1,-2)) / n
target_cov = torch.matmul(local_target, local_target.transpose(-1,-2)) / n
# 计算RMI
rmi = -torch.logdet(joint_cov) + torch.logdet(pred_cov) + torch.logdet(target_cov)
return rmi.mean()
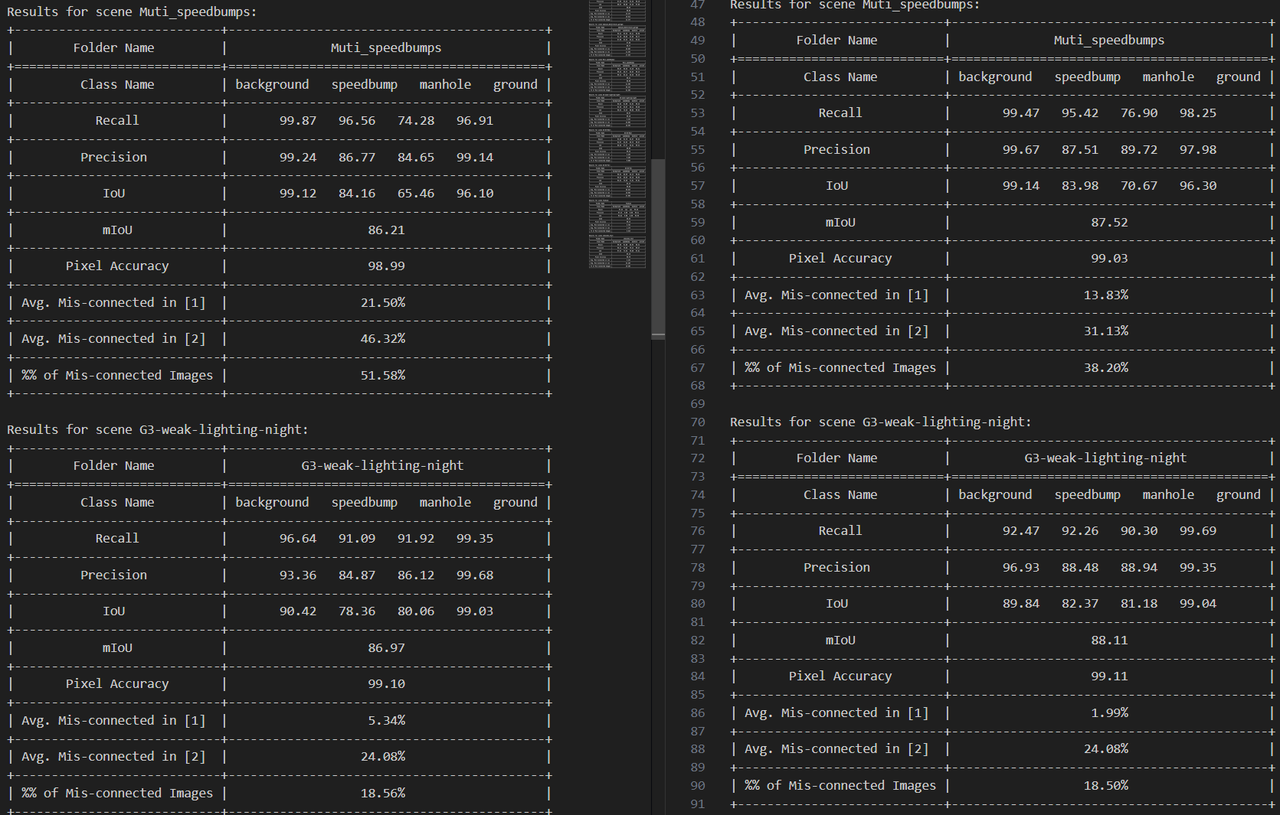
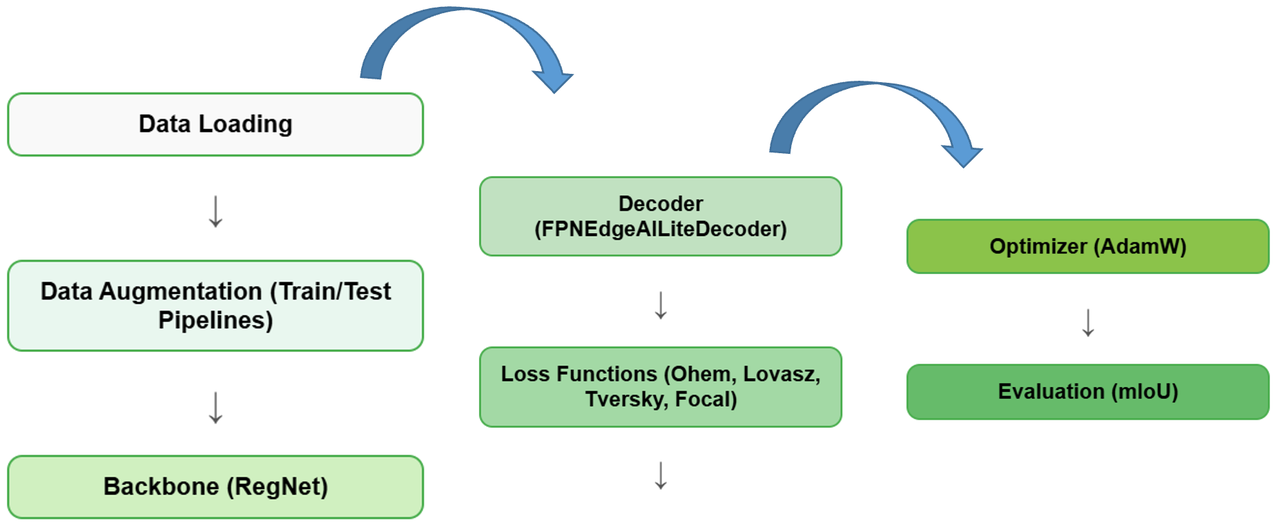
标准训练流程包含以下步骤:
QAT 训练的详细步骤:
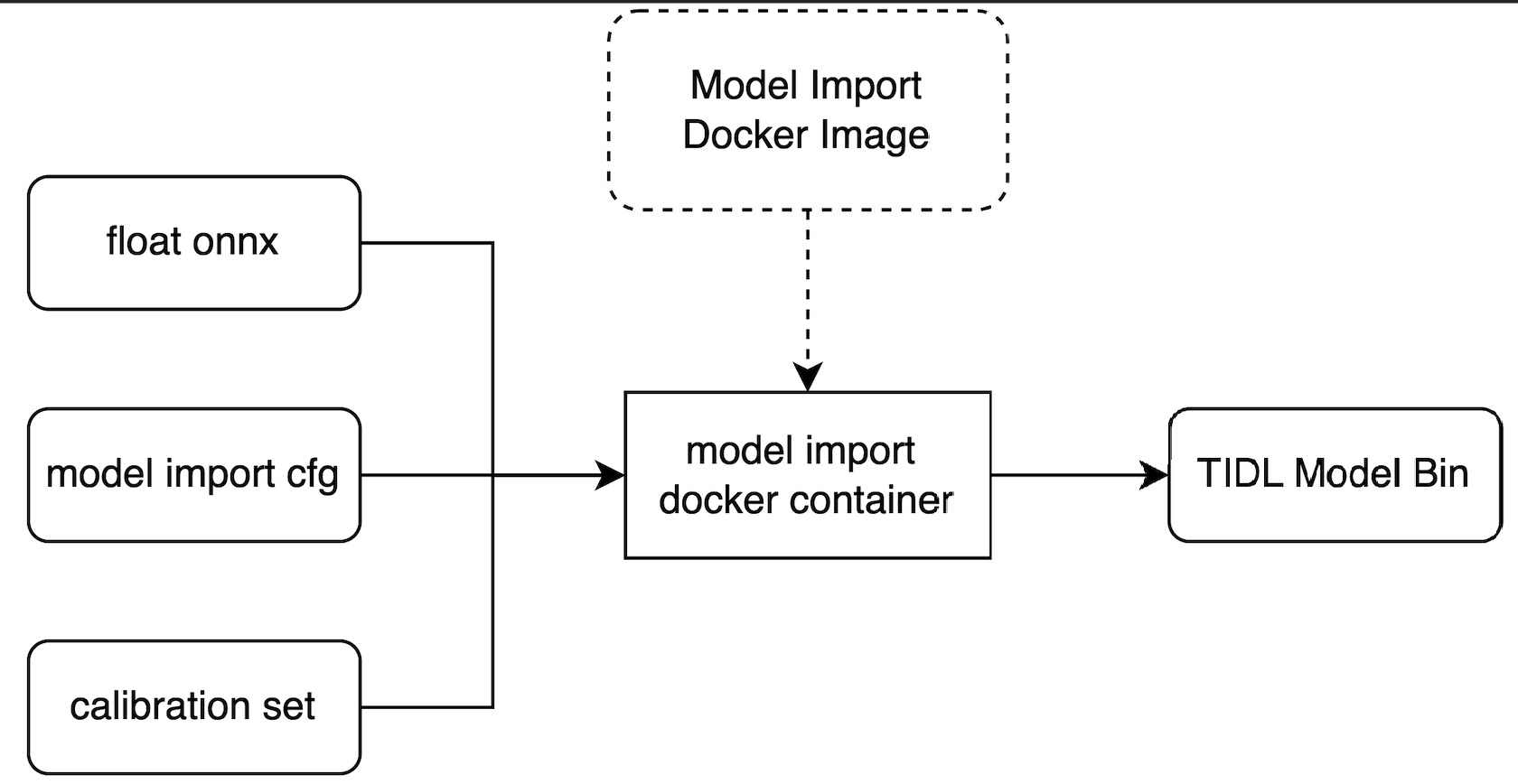
TIDLRT_invoke 执行推理。